Name your Event-Driven Architecture Design Patterns
Introduction
A few years ago I inherited a system that was sold as being bleeding edge because it was using all the latest cloud technologies. It emerged that the original designer had bought the book Serverless Single Page Apps and decided to run with it.
A key challenge that became apparent in this system was that it was hard to reason about. This is despite an enormous amount of effort and care having gone into unit testing at least some of the layers. I had to have a coffee with the departed original designer to establish the sytem context in the first instance.
In time I came to realise that the system had an event-driven architecture in all its layers, but this description is not good enough because the term has many meanings, I would have to be more precise to help the reader by naming the exact design patterns that were used. But why name the exact event-driven design patterns? It is important to do because it makes the system easier to reason about without going into implementation detail.
So, with this, in this post I’ll describe four key event-driven architecture design patterns, the first two of which were used in the cited system.
The four event-driven architecture design patterns are listed below and in turn described in greater detail further on.
- The Event Notification Pattern
- The Event-carried State Transfer Pattern
- The Event Sourcing Pattern
- The Command Query Responsibility Segregation (CQRS) Pattern
The Event Notification Pattern
Almost all systems use the event notification pattern somewhere, that is at some level.
When you call a system event-driven, the event notification pattern tends to be seen by senior engineers as a particularly important part of the architecture.
Example Application
Our example application is a retail loyalty scheme application. The dollar value of tax invoices issued to members using point of sale software are used to credit the loyalty scheme point balance of members using some business rule.
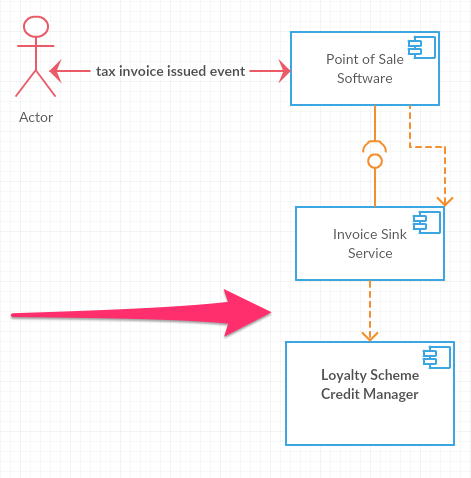
In the UML 2 component diagrams illustrated below, remember that the dashed arrows represent a dependency relationship. So in the diagram directly below the Invoice Sink Service depends on the Loyalty Scheme Credit Manager.
The coupling between the Invoice Sink Service and the Loyalty Scheme Credit Manager is something that we may not want. Put differently we may look for a way to get around the cited coupling in terms of the dependency relationship by making sure the Loyalty Scheme Credit Manager knows about the Invoice Sink Service but not the other way around. The reason why we may want to do this is because something that is very generic, such as collecting invoices from point of sale software is generally something we want to depend on rather then have it depend on many other components.
Now, the way in which we can reverse the dependency between the Invoice Sink Service and the Loyalty Scheme Credit Manager, as illustrated in directly below, is to use an event.
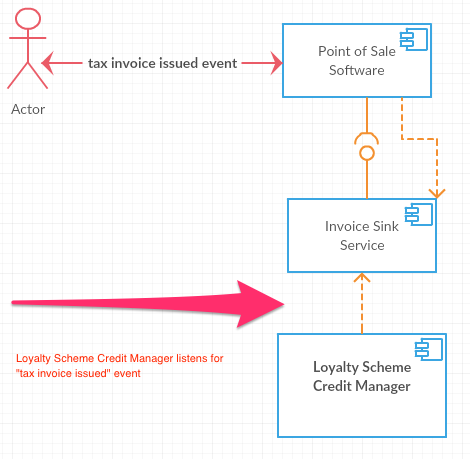
A tax invoice issued event is conceptually an example of such an event.
Events and Commands
Its worth noting that the way in which communication patterns are realised affects whether we use the term events or commands. In terms of naming tax invoice issued is an event-oriented naming style and it is not a command to any other system and this is important. The reason why it is important is because our naming style more accurately describes the system to someone that wants to understand how it works.
In terms of how events or commands are implemented, it would generally be in the same way, using say messagaes and queues. So the only difference is in naming and consequential semantics.
Additional Benefits of Using Events for Notification
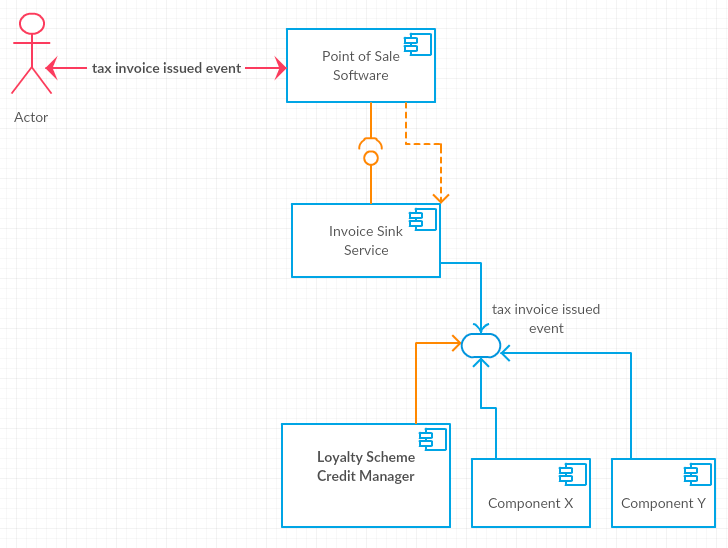
An additional benefit of the reversed dependencies between systems, and using events for notification between systems, is that it becomes easier to add additional systems or components that can listen to particular events using say publish-subscribe messaging patterns. In our example application, if there had been an “Invoice Sink Service” team in principle there would be no need to even talk to the said team to consume tax invoice issued events.
There is a particularly significant trade-off when it comes to the use of the event notification pattern. While we have, as a benefit, the decoupling of the receiver from the sender (i.e. great flexibility) we have as a drawback the difficulty in reasoning about the overall system behaviour. The latter occurs because there is no single system or codebase that can be consulted to reason about the overall system behaviour. The only way to figure out what is going on system wide is to follow or trace through the flow of messages throught the overall system. This is true when it comes to GUI software and similarly it is true is larger enterprise systems.
The Event-carried State Transfer Pattern
This is simply putting so much information into the event that going back to the source system for further detail is not necessary. For example a tax invoice issued event may contain all line item details, the payment receipt information if available and a host of other data such as the merchant. Likewise an merchant address changed event would conceivably contain the old address as well as the new address.
The overarching consideration is whether the querying load on the source system can be eliminated for unantipicated queries related to events. The answer is yes but this requires tranferring the state from the source system into a suitable data store at the target system.
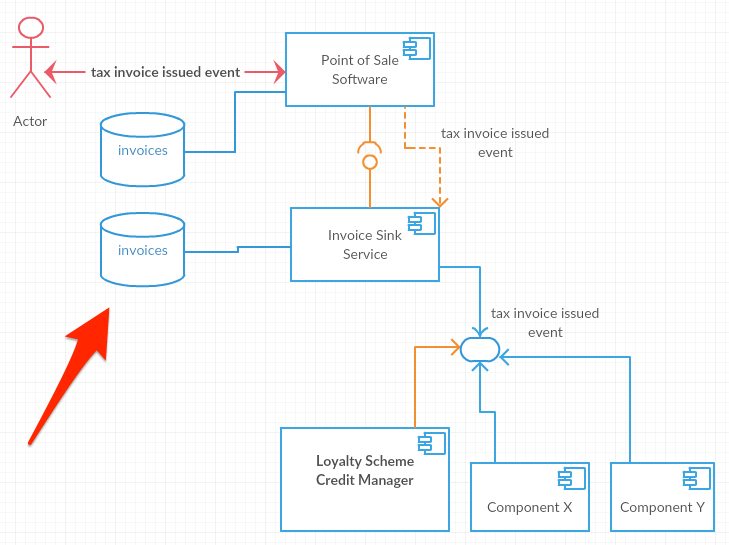
With this pattern contact initiated from the Invoice Sink Service to the Point of Sale Software is forbidden. It logically follows that the latter will keep a copy of all the data its ever going to need. So that is the trade-off, on the upside downstream systems no longer need to call the source system which may eliminate remote network calls and so enhance performance.
On the upside availablity may be improved in terms of downstream systems which can tolerate the upstream system being down. On the downside duplicate data needs to be stored. In terms of downsides, as per the CAP Theorem, the price of high availablity is a lack of consistency and so we have eventual consistency. So, we are trading off high availablity for consistency.
So in summary with Event-carried State Trasfer trade-off the following benefits.
- Decoupling.
- Reduced load on supplier (duplicating data to avoid calling back).
Against the following costs:
- Eventual consistency (due to replicated data).
The Event Sourcing Pattern
With this pattern, events that contain the details of a change are stored before being processed. The event is then processed to affect the necessary change. With this we effectively have an event log and the current application state which are two representations of the same world. The event log contains all the events that ever change the application state and that lead to its current application state. Both the event log and current application state would commonly be persisted but this in itself is not necessary to use the pattern.
In order to test that we are using the event sourcing pattern we would have to test whether we can, at any time, reproduce the current application state. The reason why we would want to do this testing is because a key benefit of the event sourcing pattern is being able to discard and rebuild the application state. An additional benefit is that you don’t need to focus on preserving the application state because it can easily be rebuilt.
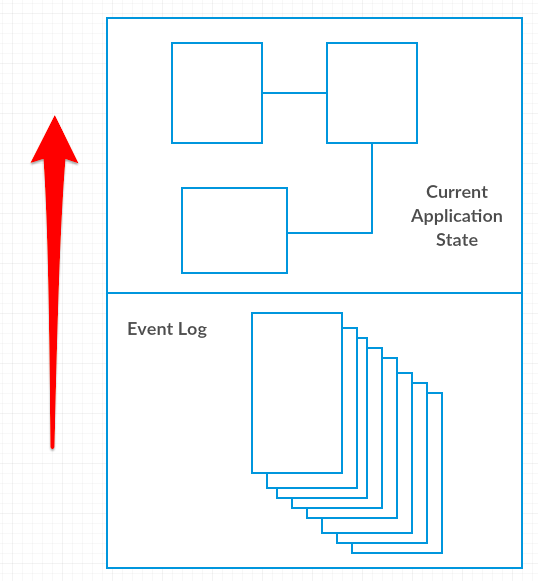
Metaphors or systems that use event sourcing:
- Version control e.g. git
- Accounting ledgers - the current application state is an account balance which is derived from every credit and debit to that account.
Key pattern benefits:
- Audit
- Debugging
- Historic State
- Alternative State - In essence storing events provides new and interesting ways to look at data when compared with a current state approach. In that regard eventstore.org says As the events represent every action the system has undertaken any possible model describing the system can be built from the events.
- Memory Image - No need to store the application state in a persistent store, the entire application state can run in memory and so this leads to high performance systems. Application developers can focus on having a rich domain model as per Domain-Driven Design by Eric Evans which in itself challenging. As systems increasingly have large amounts of non-volatile main memory this pattern becomes increasingly viable. Many systems have been built with the assumption that main memory is significantly limited (and so persistant store usage becomes mandatory), but this may no longer be the case. Entire systems can fit into main memory.
Key pattern drawbacks or downsides:
- Unfamiliar - and so harder to work with.
- External Systems - e.g. you cannot replay a call to an external system two weeks ago, you have to save every response from an external system as an event and make it a part of the replaying mechanism.
- Event Schema - the issue here is how can you store events in such a way that you are confident that you can change the replaying code that processes them. With this the event schema becomes an important consideration.
- Identifiers - when identifiers are generated it must be done in such a way that we can replay. This adds complexity as this must be thought through.
- Asynchrony [questionable] - This may be cited as a drawback, because it makes it harder to reason about a system, but note there is no need for asynchrony in an event sourced system. Asynchrony does not have to be used when using an event sourced approach. People may introduce asynchrony to enhance responsiveness but this introduces complexity.
- Versioning [questionable] - This is a potential drawback due to the ability to replay. The code in the system would be changing over time, and it would need to be compatible with the events in the event log. Or does it need to be compatible with the events in the event log? One could keep events up to a certain point in time in particular systems (e.g. a daily event log), which one could call a snapshot, so with this it’s not necessary to be overly concerned with the versioning aspect. Naturally this would not be possible in some systems and there is advice on how to deal with this.
- Rolling Snapshots - Given that it may become impractical to replay millions of events we would need to introduce storing the state when all events of a particular type up to a point have been replayed. This adds complexity.
Note [Event Store], “the stream database written from the ground up for event sourcing”, has useful Event Sourcing Basics reference material. I would recommend reading all the subsections because for example the how to deal with Rolling Snapshots is good to know about.
The Command Query Responsibility Segregation (CQRS) Pattern
With this when we have a persistent store, we have a Query Model, which deals with reads, that is distinct from a Command model, which deals with updates, each with its own distinct service interfaces. With this you seperate the components that read and write from your persistent store. To be clear these components are seperate pieces of software i.e. modules. They may or may not be seperated at run-time.
The question is, when is this pattern appropriate? What are the trade-offs? Do teams get in trouble when using this pattern (as Martin Fowler suggests) and if so why? I’ll adress these further on.
It may be worth noting what Martin Fowler has stated, which is that this pattern often gets confused when people claim CQRS should be used in all systems because of how useful it is to have the seperate models for reading things and populating different models. As Folwer states, at the persistance layer we have been using seperate operational databases (online transaction processing databases) and reporting databases for a very long time and this pattern is almost unversally pervasive. That said, the separation of the update model from the read model in the service layer is rare.
It is interesting to read the Microsoft treatment of the pattern in conjunction with my most recent experience of applying Robert C. Martin’s Clean Architecture in an ambitious content management product development effort. In my mind we faced problems similar to what they mention relating to the same POJO being used for read and write operations. An interesting question is whether CQRS would apply at the core layer, that is when it comes to the Domain Driven Designed core layer, or only at specific layers such as at the interactor layer. Robert C. Martin’s Clean Architecture is certain more complex than the traditional CRUD design mentioned in the Microsoft documentation because traditional CRUD designs don’t have a clean core layer.
Useful References
- Serverless Single Page Apps - Fast, Scalable and Available - Ben Rady, The Pragmatic Bookshelf, 2016
- The Many Meanings of Event-Driven Architecture - Martin Fowler, GOTO Conference, Chicago 2017
- What do you mean by “Event-Driven” - Martin Fowler, 07 February 2017
- Event-Driven Architecture - Mark Richards, Software Architecture Patterns, O’Reilly Media, February 2015
- Event-driven architecture style
- Building Event-Driven Microservices with Event Sourcing and CQRS (Lidan Hifi, Israel)
- Event Sourcing Basics
- Versioning in an Event Sourced System
- Versioning of Events in Event Sourced Systems
- Command and Query Responsibility Segregation (CQRS) pattern
- CQRS